Network Architecture
The overview of FreeAnimate. We introduce a novel network architecture that combines a U-Net with ControlNet, offering a more efficient approach to incorporating reference image content and structure into the U-Net without relying on CLIP image encoder or Appearance Net.
Specifically, our method incorporates three crucial components in addition to the basic SD model: Control branch, Inversion-Boosted Attention, and Reference-Anchored Self-Attention.
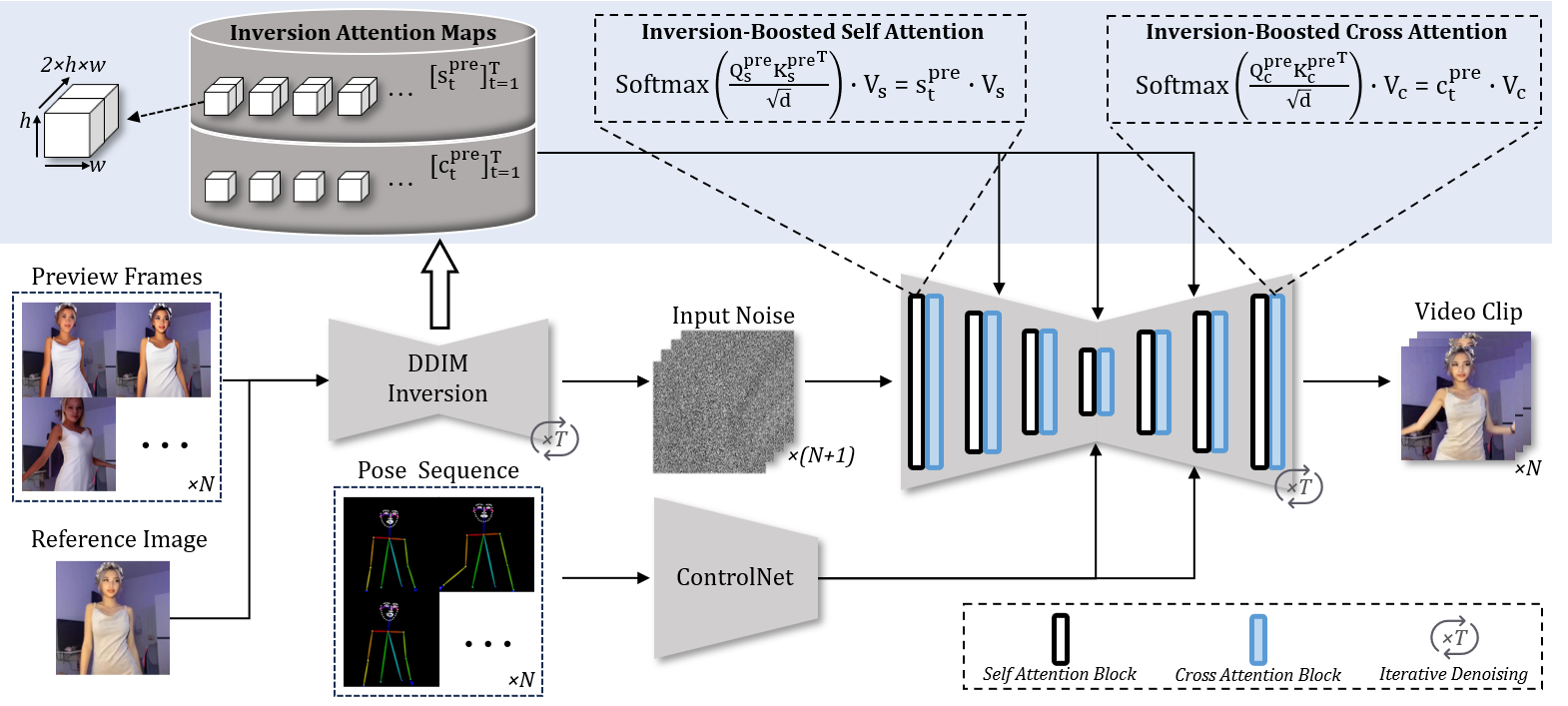
Control Branch
The Control Branch is responsible for effectively incorporating pose guidance into the generation process. It leverages a pre-trained ControlNet to encode the pose sequence and injects this information into the U-Net. Unlike traditional methods that require additional training or fine-tuning, our approach utilizes ControlNet as a plug-and-play module, enabling the model to directly align generated frames with the provided pose sequence. This setup avoids the need for large-scale training and ensures that the generated video follows the desired pose sequence while maintaining computational efficiency.
Inversion-Boosted Attention
Inversion-Boosted Attention (IBA) improves temporal consistency by leveraging attention maps extracted from preview frames
during DDIM inversion. These maps refine both self- and cross-attention, enhancing video coherence and structural stability.
Inspired by FateZero, IBA uses DDIM inversion attention maps to guide denoising. At each step \( t \), we store the
self-attention maps \( \left[\textit{s}_{t}^{\text{pre}}\right]_{t=1}^{T} \) and cross-attention maps
\( \left[\textit{c}_{t}^{\text{pre}}\right]_{t=1}^{T} \) as follows:
\[
z_{T},\left[\textit{s}_{t}^{\text{pre}}\right]_{t=1}^{T},\left[\textit{c}_{t}^{\text{pre}}\right]_{t=1}^{T}=
\operatorname{DDIM-INV}\left(z_{0}\right).
\]
where \( \operatorname{DDIM-INV} \) represents the DDIM inversion process. During denoising, these attention maps refine the attention computation:
\[
\text{SELF-ATT}=
\operatorname{Softmax} \left(\frac{Q_{s}^{\text{pre}} {K_{s}^{\text{pre}}}^T}{\sqrt{d}}\right) \cdot V_{s}
=\textit{s}_{t}^{\text{pre}} \cdot V_{s},
\]
\[
\text{CROSS-ATT}=
\operatorname{Softmax} \left(\frac{Q_{c}^{\text{pre}} {K_{c}^{\text{pre}}}^T}{\sqrt{d}}\right) \cdot V_{c}
=\textit{c}_{t}^{\text{pre}} \cdot V_{c}.
\]
Here, \( Q_{s}^{\text{pre}}, K_{s}^{\text{pre}}, V_{s} \) and \( Q_{c}^{\text{pre}}, K_{c}^{\text{pre}}, V_{c} \) denote the
query, key, and value projections for self- and cross-attention, respectively, with \( d \) being the attention feature dimension.
By leveraging precomputed self- and cross-attention maps, IBA helps preserve motion integrity and spatial structure while reducing
artifacts. These maps act as guidance signals, improving both temporal coherence and structural alignment during generation.
Reference-Anchored Self-Attention
Reference-Anchored Self-Attention (RA-SA) improves temporal consistency by anchoring frames to a reference image.
By integrating both the current and reference latents, RA-SA enhances identity preservation throughout the video.
Specifically, \( \text{SELF-ATTENTION}(Q, K, V) \) for the latent code \( z^{i}_{t} \) of frame \( i \) at time step \( t \) is computed as:
\[
Q = W^{Q} z^{i}_{t}, \quad K = W^{K}\left[z^{i}_{t} ; z^{a}_{t}\right], \quad V = W^{V}\left[z^{i}_{t} ; z^{a}_{t}\right].
\]
where \( W^Q \), \( W^K \), and \( W^V \) are projection matrices from the U-Net, and \( \left[\cdot\right] \) denotes concatenation.
\( z^{i}_{t} \) and \( z^{a}_{t} \) represent the latents of the current and anchor frames, respectively. While **Pixel2Video** and **FateZero**
set \( a \) to \( 1 \) and \( \left\lfloor \frac{N}{2} \right\rfloor \), we use \( I_{ref} \) as the anchor frame for improved alignment.
During DDIM inversion, RA-SA replaces standard self-attention, modifying the self-attention map dimensions from \( R^{hw \times hw} \) to \( R^{hw \times 2hw} \).
In the denoising process, query and key features originate from DDIM inversion attention maps, while value features are computed dynamically using the current and reference latents:
\[
Q = W^{Q} z^{i}_{t}, \quad K = W^{K}\left[z^{i}_{t} ; z^{a}_{t}\right], \quad V = W^{V}\left[z^{i}_{t} ; z^{a}_{t}\right].
\]